Advanced Quantization
By representing weights using ternary values {-1, 0, +1}, the model achieves a 6.4x reduction in size while retaining intricate details, textures, and prompt alignment.
Pollo AI: Free All-in-One AI Image and Video Generator
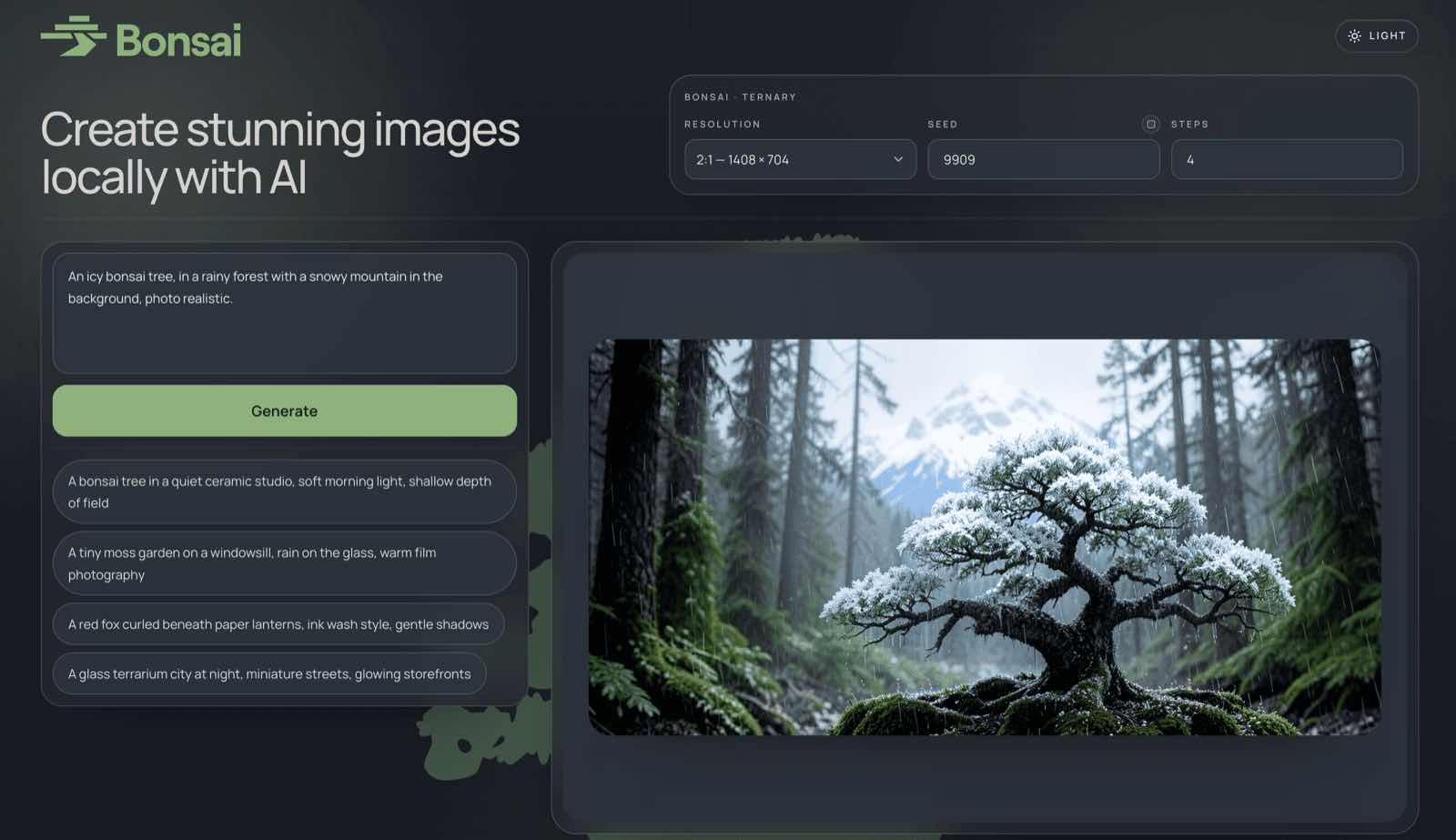
Based on the FLUX.2 Klein 4B architecture, Bonsai Image keeps the powerful diffusion transformer intact while changing how weights are represented. The result is lightweight, fast, and highly capable generation.
Ternary Precision
95% Quality Retention
Sub-Second Latency
FLUX.2 Klein DNA
Resource-Efficient Backend
Apache 2.0 Open Source
Traditional diffusion models require massive, power-hungry server clusters, driving up subscription costs and slowing down generation times. Bonsai Image solves this by shrinking the diffusion transformer from 7.75 GB to as little as 1.21 GB with minimal loss in visual fidelity.

A lighter model means a faster, more accessible creative flow. Here is how Bonsai Image optimizes your digital art workflow at bonsaiimage.com.

Whether you are using our online generator or running it locally, optimize your setup for high-fidelity results.
Use the Ternary model (1.21 GB) for balanced high-fidelity details, or switch to the 1-Bit model (0.93 GB) for maximum speed and lower footprint.
Leverage the underlying FLUX.2 architecture. Describe your scene naturally, including details about subject matter, lighting, style, and camera angles.
For high-aesthetic fidelity on our playground, 20-30 steps provide an excellent sweet spot. Adjust your settings dynamically in the sidebar.
Download your generated assets directly, or grab the open weights from Hugging Face to integrate Bonsai directly into your local workflows.
Bonsai Image isn't just compressed; it is mathematically optimized to extract maximum performance out of every single bit.
The real metrics behind the industry's most compact, high-fidelity diffusion model.
1.21 GB
Model Size (Ternary)
Compressed 6.4x from the uncompressed 7.75 GB baseline for efficient hosting.
~95%
Quality Retained
Tested retention of original FLUX.2 Klein visual fidelity and prompt alignment.
< 6s
Generation Speed
Blazing-fast generation on standard hardware, with near-instant rendering online.
Discover why developers and prompt designers are choosing Bonsai Image's balanced approach.
Creative Lead
Ad Agency
Fullstack Developer
SaaS Builder
Digital Illustrator
Freelance
Everything you need to know about Bonsai Image and how to use it online.